ウェアラブル端末が周囲までの距離(深度)を把握できれば、障害物検知や見守りなどに役立つ一方で、従来手法は計算資源や専用ハードウェアへの依存、そしてカメラによる常時撮影に伴うプライバシー懸念が普及の障壁となってきた。
高精度な単眼深度推定は深層学習の活用で進展しているが、推論のための計算量・メモリ・消費電力が大きく、ウェアラブル級の制約下では運用が難しい。ToF/LiDAR等の専用深度センサーは小型化・コスト・実装制約の課題が残り、さらにRGB映像の取得・保存はプライバシーリスクを高めるため「必要最小限の形状情報だけを得る」設計が求められる。
計算資源が限られプライバシー配慮が必須なユビキタス環境で、単眼カメラのみから深度を連続値で復元せずに“閾値判定(近い/遠い等)”として高速・高精度に得る方法を実現する。
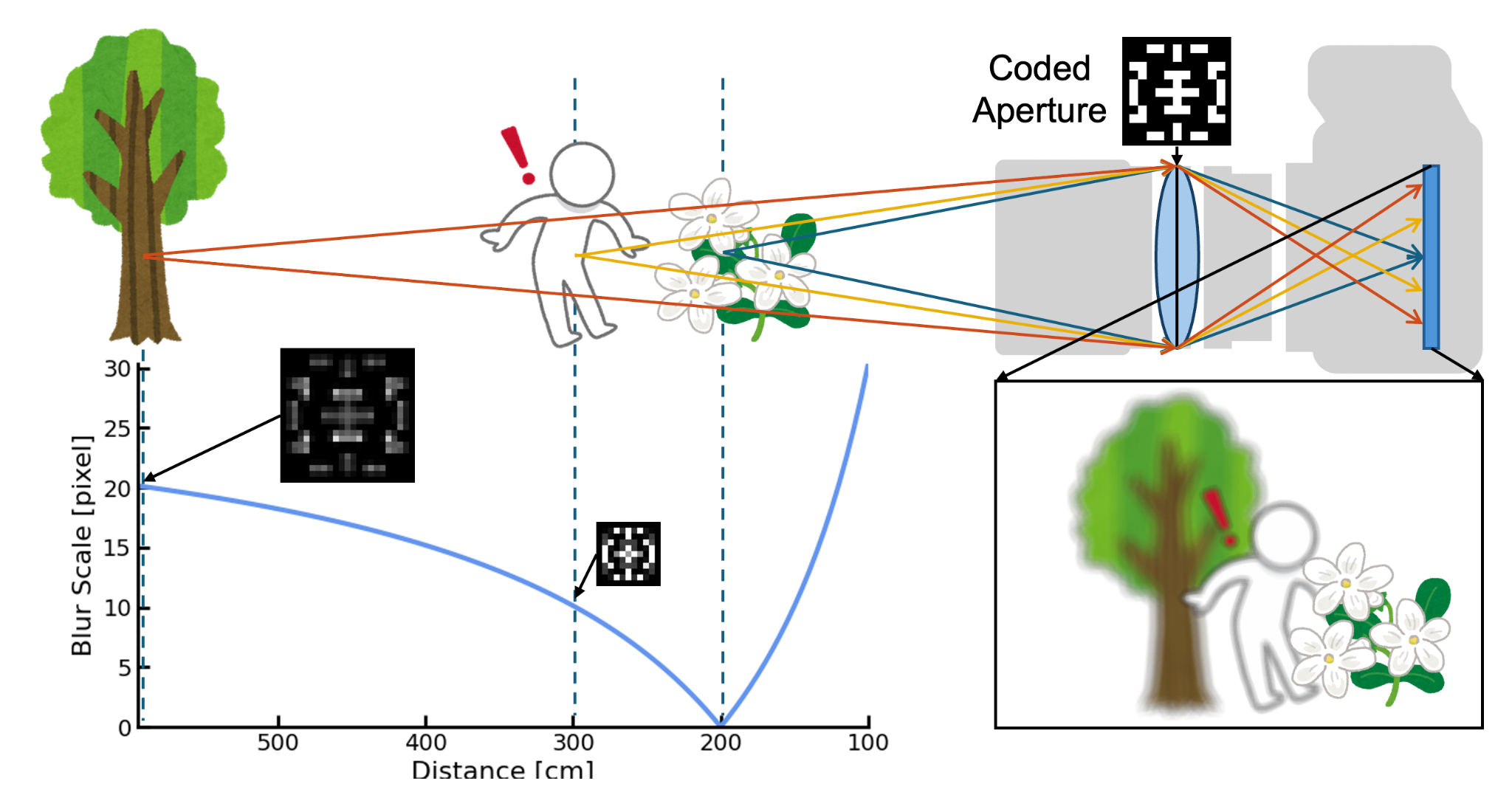
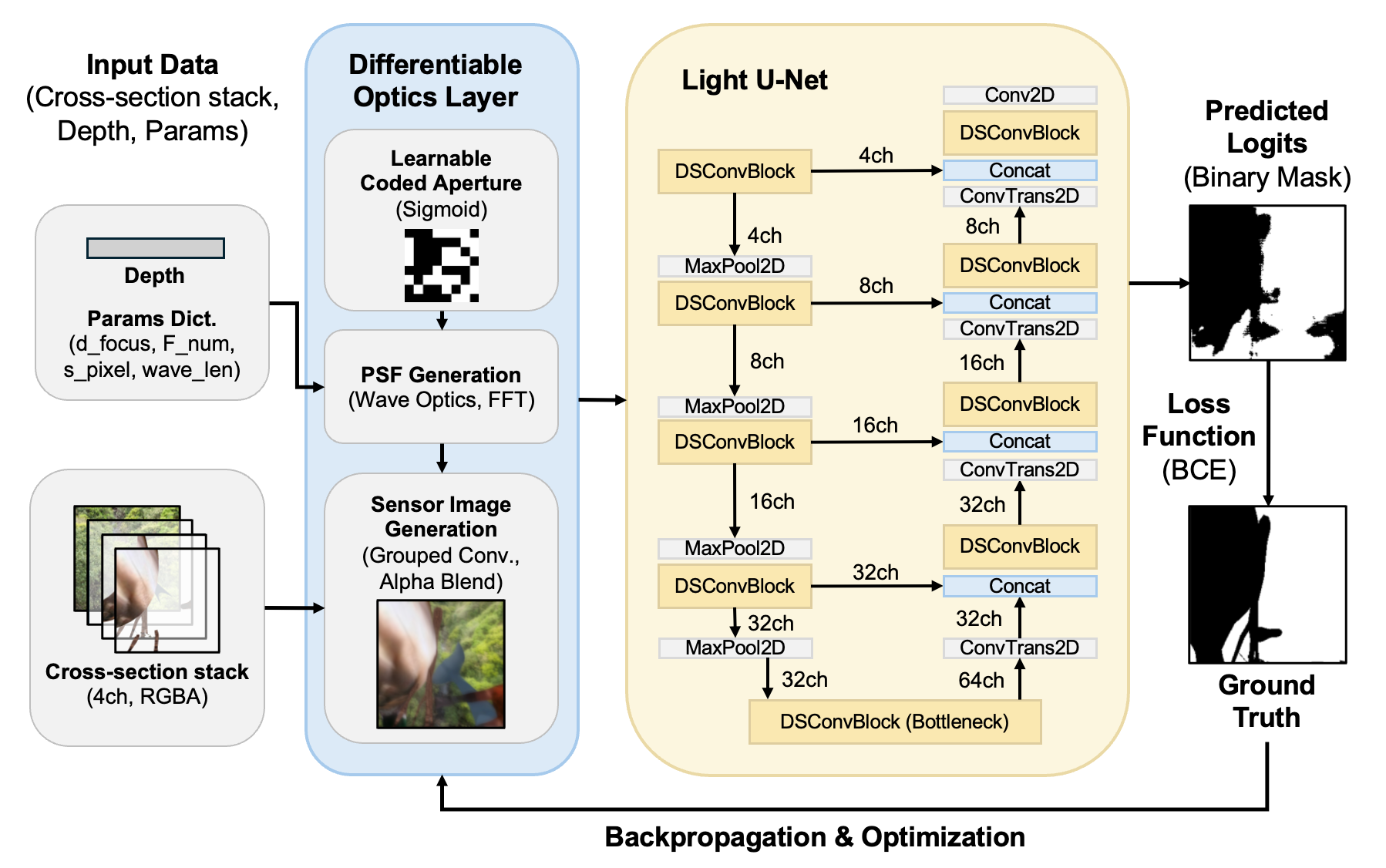
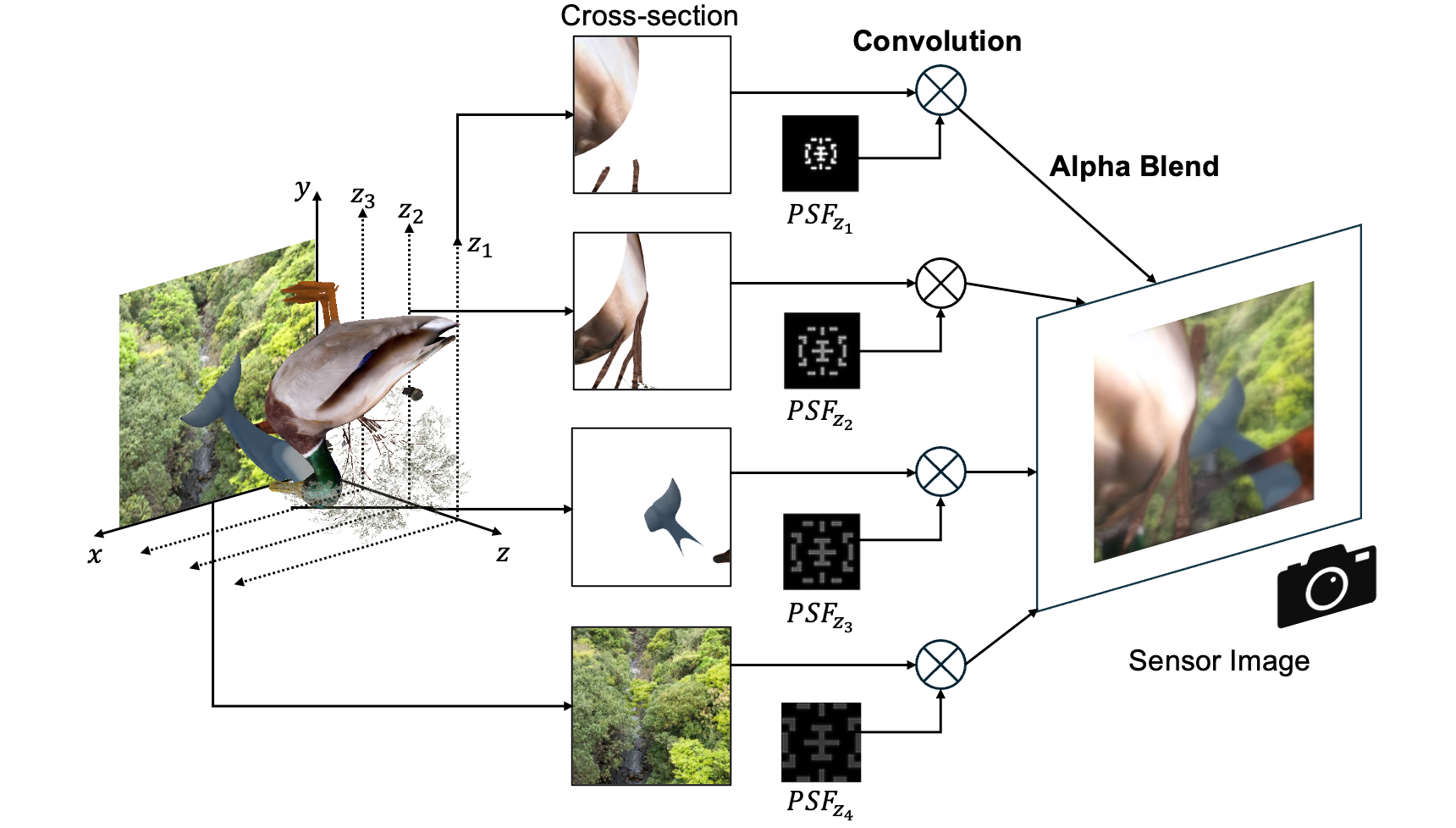
レンズ開口に符号化開口を導入して点拡がり関数(PSF)の深度依存性という光学的手掛かりを画像に埋め込み、深度推定ではなく深度閾値分類マップを直接出力する枠組みを採用する。さらに、微分可能光学系と軽量ニューラルネットワークを組み合わせることで、開口パターンと推定器を同時に最適化し精度と速度を両立させる。
提案法は、深度閾値分類におけるピクセル精度を約85%の水準で維持しながら、推論を3〜4ミリ秒まで高速化できることを示した。最適化された符号化開口を用いることで、限られた計算資源でもリアルタイム動作が可能であり、かつアプリケーションに必要な最小限の形状情報に留めることでプライバシーの保護にも資することを実証した。
While wearable devices capable of depth perception are valuable for obstacle detection and monitoring, their widespread adoption has been hindered by reliance on heavy computational resources, the need for specialized sensors, and privacy concerns associated with constant camera recording.
Although deep learning has advanced high-precision monocular depth estimation, its high inference cost, memory usage, and power consumption make it difficult to operate under wearable constraints. Furthermore, dedicated sensors like ToF and LiDAR face challenges regarding miniaturization and cost, while capturing RGB video heightens privacy risks. Consequently, there is a need for designs that acquire only the “minimum necessary shape information.”
To address these issues in resource-constrained, privacy-critical ubiquitous environments, we propose a method to achieve high-speed, high-precision depth thresholding using only a monocular camera. Instead of restoring continuous depth values, our approach performs a “threshold classification” (e.g., near vs. far). We adopt a framework that introduces a coded aperture to the lens, embedding the optical cue of the Point Spread Function’s (PSF) depth dependency into the image to directly output a depth threshold classification map. By combining differentiable optics with a lightweight neural network for joint learning, we simultaneously optimize the aperture pattern and the estimator to balance accuracy and speed.
Our results demonstrate that the proposed method accelerates inference to 3–4 ms while maintaining a pixel accuracy of approximately 85% in depth threshold classification. We verified that using an optimized coded aperture enables real-time operation even with limited computational resources and contributes to environmental privacy protection by restricting data to the minimum shape information required for applications.
Zhang Yuke, Takaki Ken, Horisaki Ryoichi, Kawahara Yoshihiro, Sasatani Takuya
連絡先/Contact
zhangyuke@akg.t.u-tokyo.ac.jp, sasatani@g.ecc.u-tokyo.ac.jp