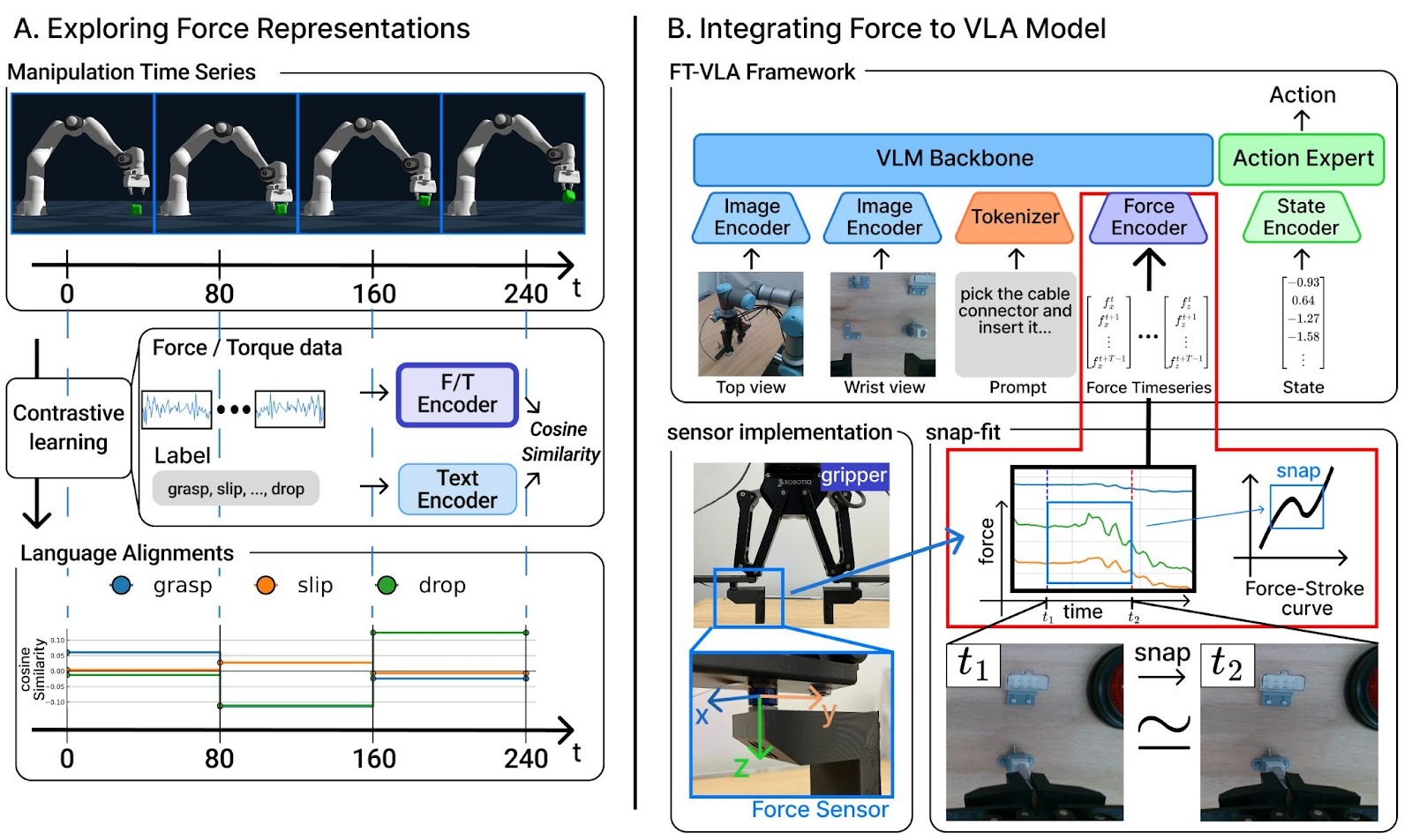
人間のように「見て、触れて、理解する」汎用ロボットの実現には、視覚情報だけでなく、指先から伝わる微細な「力覚」を高度に活用する技術が不可欠である。従来の行動生成モデル(VLA)は主に視覚と言語の統合に依拠しており、視覚的な死角が生じる作業や繊細な力加減を要する場面において、適切な判断が困難であるという課題があった。
本研究は、力覚の時系列データに潜む意味情報を抽出・活用することで、視覚に過度に依存しない頑健な行動生成フレームワークの構築を目的とする。
具体的には、対照学習を用いて物理事象と言語表現を結びつける力覚エンコーダを開発し、さらに差し込み時の手応え(F-S特性)を捉えて視覚・言語情報と動的に融合する行動生成モデルを構築した。実機による端子差し込みタスクの検証において、本手法は視覚のみの手法に比べ成功率を20%以上向上させた。
また、動作完了を自律的に判断することで、次タスクへの移行時間を最大18.19秒から4.87秒以下へと大幅に短縮し、迅速かつ確実な完遂を実現した。
本成果は、精密な組み立てを要する電子機器分野など、ロボットが活躍できる産業領域を大幅に広げる次世代の基盤技術となる。
To realize general-purpose robots capable of “seeing, touching, and understanding” like humans, technologies that highly utilize “force-torque sensing” transmitted from fingertips are increasingly essential. Conventional Vision-Language-Action (VLA) models rely heavily on visual-linguistic integration, which presents inherent limitations in tasks involving visual occlusions or requiring delicate force adjustments. This study aims to construct a robust action generation framework that extracts and utilizes semantic information hidden within force-torque time-series data to reduce over-reliance on vision. Specifically, we developed a haptic encoder that aligns physical phenomena with linguistic expressions through contrastive learning and constructed an action generation model that dynamically fuses Force-Stroke (F-S) characteristics with visual and linguistic modalities. In real-world connector insertion experiments, the proposed method improved the success rate by over 20% compared to conventional vision-based methods. Furthermore, by enabling the autonomous determination of task completion, the transition time to subsequent tasks was significantly reduced from a maximum of 18.19 seconds to under 4.87 seconds. These results constitute a foundational next-generation technology that significantly expands the industrial scope of robotics, particularly in fields such as precision electronics assembly.
Kazuki Takahashi, Ryota Sakuma, Hiroaki Murakami, Mitsuhiro Kamezaki, Yoshihiro Kawahara
関連論文/Related Publications
髙橋和希,石毛真修,佐久間亮太,津村拓鋭,朴来炫,劉順,村上弘晃,亀﨑允啓,川原圭博,
“CLIP を用いた力覚時系列のアライメントに関する検討,” 第43回日本ロボット学会学術講演会, 1M4-05, 2025.
連絡先/Contact
kazuki.takahashi@akg.t.u-tokyo.ac.jp